Introduction
A data pipeline is a series of data processing steps where data is ingested from various sources, transformed, and then delivered to a destination for analysis and insights. The concept has become integral in handling large volumes of data efficiently.
Components of a Data Pipeline
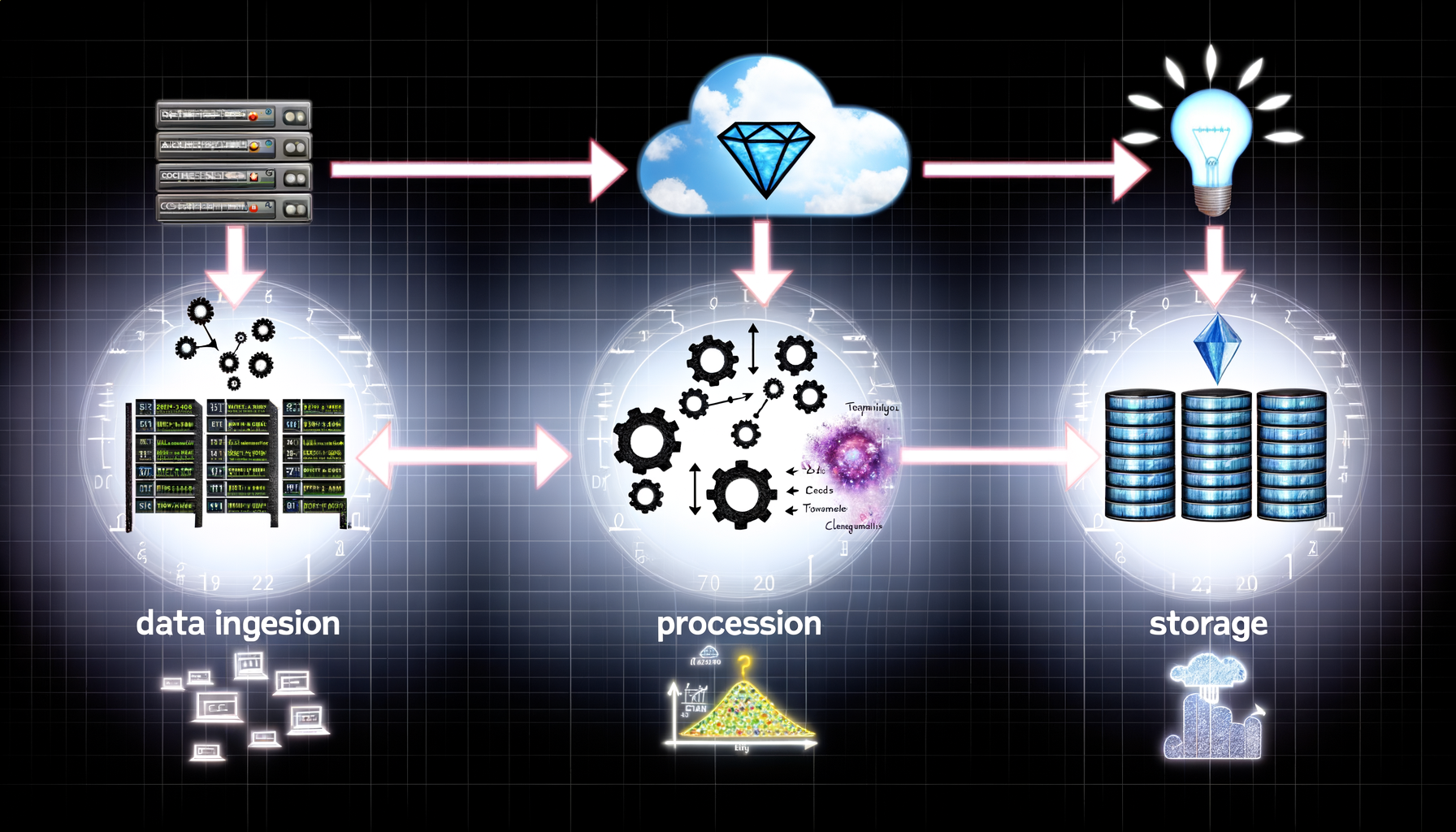
Data pipelines typically consist of three key components: ingestion, processing, and storage. These components work together to ensure data moves seamlessly from its source to its destination.
Ingestion
Ingestion is the first step where data is collected from different sources. This could be databases, APIs, or live streams. Effective ingestion is crucial for the overall efficiency of the pipeline.
Processing
Once ingested, data needs to be processed. This step could involve cleansing, duplicating, or transforming the data. Processing is essential to ensure the data is ready for analysis.
Storage
After processing, the data is stored in a data warehouse, data lake, or another storage solution. Efficient storage solutions enable quick retrieval for future analysis.
Types of Data Pipelines
Data pipelines can be batch or real-time. Batch pipelines process data at set intervals, whereas real-time pipelines handle data as it comes in. The choice depends on the business requirement.
Benefits of Data Pipelines
Data pipelines offer numerous benefits, including improved data quality, increased efficiency, and better insights from data. They also automate data movement, reducing human error.
Challenges
Building and maintaining data pipelines come with challenges. These include handling large volumes of data, ensuring data quality, and managing complex architectures.
Conclusion
Data pipelines are essential for modern data management. They streamline the process of collecting, processing, and storing data, making it easier for businesses to gain valuable insights. Despite the challenges, their benefits make them indispensable in today’s data-driven world.
View the original article here: https://boomi.com/blog/what-is-a-data-pipeline/